RAG AI学习助手
NVIDIA AI-AGENT夏季训练营
项目名称:AI-AGENT夏季训练营 — RAG AI学习助手
报告日期:2024年8月18日
项目负责人:LeAf
项目概述
本项目旨在开发一款集成了AI诗词问答和看图写作功能的RAG智能对话助手。该助手能够根据用户提供的诗词问题,基于RAG进行问答,同时也能够对用户上传的图像进行智能分析和生成相应的中英文作品。支持文本/语音/图像输入,以及文本和语音输出。项目可以应用于课本知识问答、图文创作辅助等AI教学场景。
技术方案与实施步骤
模型选择
本项目的大模型采用了SaaS模型,选取了NVIDIA的Nim中meta/llama-3.1-405b-instruct以及Amazon的Bedrock中的claude3.5。其中llama-3.1-405b-instruct是目前最大的开源基础模型,并且可以本地化部署,适配场景广泛。而claude3.5拥有很强的图片理解能力,有助于更好适配本次看图写作的场景。 考虑到私域知识的场景,采用了Nim中的snowflake/arctic-embed-l向量模型;通过RAG模型在生成式任务中融合了检索式组件,能够从知识库中获取相关信息,并将其与生成模型的输出进行融合,从而提高了生成的准确性和丰富度。
数据的构建
- 针对诗词问答任务,通过从网络上收集了大量优秀古典诗词作品(如《唐诗三百首》),构建了一个诗词知识库,并对知识库中的诗词数据进行了向量化处理,同时构建了引文、作品名、作者等元数据信息。
- 针对看图说话任务,目前基于大模型自身的图片理解能力,构建场景prompt。后续也考虑收集相关教学材料进行RAG补充,以丰富和匹配实际教学场景。
功能整合
除了核心的LLM以及RAG模型外,我们还整合了语音、图片等多模态交互功能。通过语音ASR和TTS功能以更好的实现交互对话;另一方面通过图片交互以及结合OpenCV进行图片压缩处理以丰富场景并节省模型的token耗费。
实施步骤
环境搭建
- 使用conda构建python环境,并安装相关库,包括PyTorch、HuggingFace、Langchain、OpenCV、Funasr、Faiss、edge_tts、Gradio等。
- 部署并配置RAG向量模型, 构建向量库。
- 部署并配置FunASR以及EdgeTTS模型。
- 配置Nvidia以及Bedrock API,使用云端模型算力。
- 部署并配置Gradio实现GUI前端交互。
代码实现
- 构建并预处理诗词知识库
embedder = NVIDIAEmbeddings(model="snowflake/arctic-embed-l") # 只需要执行一次,后面可以重读已经保存的向量存储 text_splitter = CharacterTextSplitter(chunk_size=500, separator="\n") docs = [] metadatas = [] for i, d in enumerate(documents): try: splits = text_splitter.split_text(d) docs.extend(splits) metadatas.extend([{"source": sources[i],"title": titles[i], "author": authors[i]}] * len(splits)) except: print("error",i) store = FAISS.from_texts(docs, embedder, metadatas=metadatas) store.save_local(folderpath+"/nv_embedding")
- 开发诗词助手场景,实现RAG模型的检索和生成逻辑,集成诗词问答
def llm_chat_RAG(text, model_id="",api_key=""): llm = ChatNVIDIA(model="meta/llama-3.1-405b-instruct", nvidia_api_key=api_key, max_tokens=512) embedder = NVIDIAEmbeddings(model="snowflake/arctic-embed-l") store=FAISS.load_local(".kb/nv_embedding", embedder,allow_dangerous_deserialization=True) retriever = store.as_retriever(search_type="mmr",search_kwargs={'k':10,'fetch_k':50}) prompt1 = ChatPromptTemplate.from_messages( [ ( "system", "You are a poem assistant which can help answer poem related questions. Answer solely based on the following context:\n<Documents>\n{context}\n</Documents>", ), ("user", "{question}"), ] ) chain1 = ( {"context": retriever, "question": RunnablePassthrough()} | prompt1 | llm | StrOutputParser() ) ai_msg=chain1.invoke(text) return ai_msg.content - 语音识别、语音生成功能与LLM模型集成。
def send_msg(audio, text): try: if text: stt_ret = text logging.info(f"文字输入内容:{stt_ret}") if audio: # 创建一个示例的 int16 音频数据 int16_audio_data = np.array(audio[1], dtype=np.int16) # 创建一个临时文件来存储录制的音频数据 output_file = "out/" + common.get_bj_time(4) + ".wav" print(output_file) # 使用 scipy.io.wavfile 将数据保存为 WAV 文件 wavfile.write(output_file, audio[0], int16_audio_data) res = asrmodel.generate(output_file) stt_ret = res[0]['text'] logging.info(f"语音识别内容:{stt_ret}") # llm调用stt_ret,返回值chat_ret chat_ret=llm_chat(stt_ret,"meta/llama-3.1-405b-instruct",api_key) logging.info(f"对话返回:{chat_ret}") audio_path = "out/"+"output1.mp3" communicate = edge_tts.Communicate(chat_ret, VOICE) communicate.save_sync(audio_path) logging.info(f"合成音频输出在:{audio_path}") return audio_path, chat_ret,stt_ret except Exception as e: logging.error(f"Error processing audio: {str(e)}") return None - 开发看图说话场景,构建图片处理逻辑,与LLM模型集成。
def llm_chat_with_image(img_path): image=compress_and_encode_image(img_path) llm = ChatBedrock( model_id="anthropic.claude-3-5-sonnet-20240620-v1:0", model_kwargs=dict(temperature=0), ) messages = [ { "role": "user", "content": [ { "type": "image", "source": { "type": "base64", "media_type": "image/jpeg", "data": image } }, { "type": "text", "text": "你是一个专业老师,请根据图片内容撰写100字以内的英文小作文,并提供相应的中文翻译。" } ] } ] print(messages) ai_msg = llm.invoke(messages) return ai_msg.content - 设计并实现用户界面,支持多模态输入和输出。
with gr.Blocks() as demo: # 创建 Tab 组件,用于容纳不同的页面 with gr.Tab("诗词助手") as tab1: with gr.Row(): with gr.Column(scale=2): record = gr.Audio(interactive=True, sources=["microphone"]) text_input = gr.Textbox(label="输入文本", lines=7) submit_button = gr.Button("发送") with gr.Column(scale=1): gr.Image(label="AI",value="shiren.gif",height=400) # 添加一个空的Textbox来增加间距 with gr.Row(): gr.Textbox(value="", visible=False, interactive=False, label="") with gr.Row(): with gr.Column(): resp_display = gr.Textbox(label="AI回复",lines=8) with gr.Column(): # 创建一个音频播放器组件,它将使用音频路径来加载音频 audio_player = gr.Audio(interactive=False, label="输出音频", autoplay=True) submit_button.click( send_msg, inputs=[record, text_input], outputs=[audio_player, resp_display,text_input], js=reset_record ) with gr.Tab("看图说话") as tab2: with gr.Row(): with gr.Column(scale=2): picpath=gr.Image(label="上传图片",type="filepath",height=350) submit_button = gr.Button("发送") with gr.Column(scale=1): gr.Image(label="AI",value="teacher.gif",height=400) # 添加一个空的Textbox来增加间距 with gr.Row(): gr.Textbox(value="", visible=False, interactive=False, label="") with gr.Row(): with gr.Column(): resp_display = gr.Textbox(label="AI回复",lines=8) with gr.Column(): # 创建一个音频播放器组件,它将使用音频路径来加载音频 audio_player = gr.Audio(interactive=False, label="输出音频", autoplay=True) submit_button.click( send_pic, inputs=[picpath], outputs=[audio_player, resp_display], js=reset_record )
测试与调优
由于时间关系,测试与调优部分从简,待后续完善。
- 通过简化的测试用例以及页面测试验证功能的正确性。
- 通过应用场景下的效果测试情况,进行模型Prompt和参数调整。
项目成果与展示
应用场景展示
本项目开发的AI诗词助手及AI看图说话功能,可以广泛应用于课本知识问答、图文创作辅助等场景。
1.AI诗词助手
用户可以通过文本或语音输入诗词相关问题,助手会语音解答相关的诗词含义。
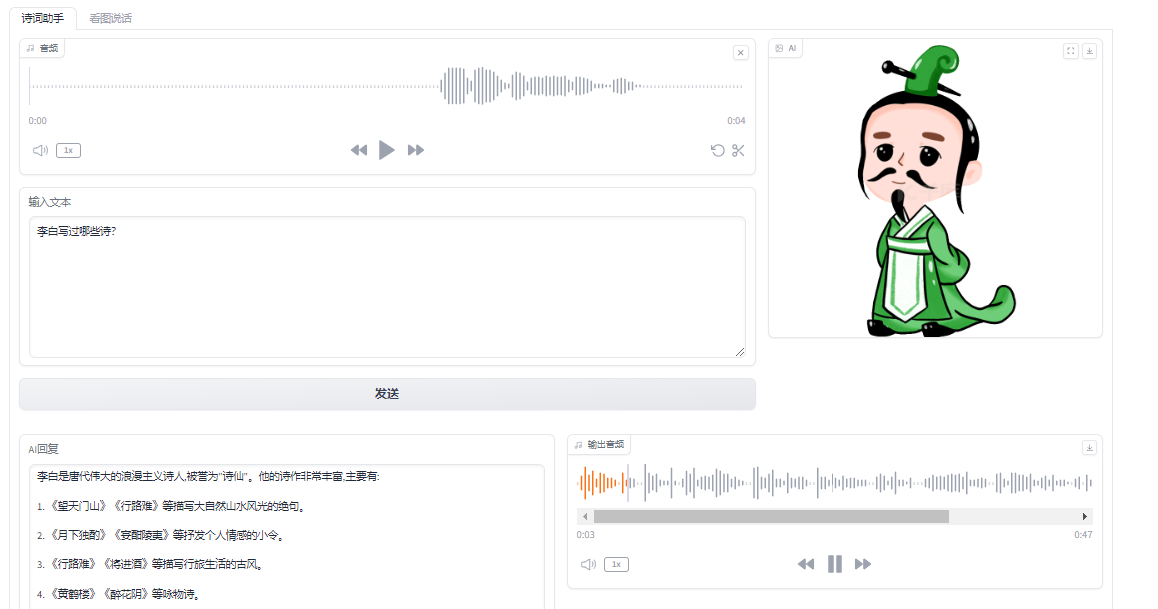
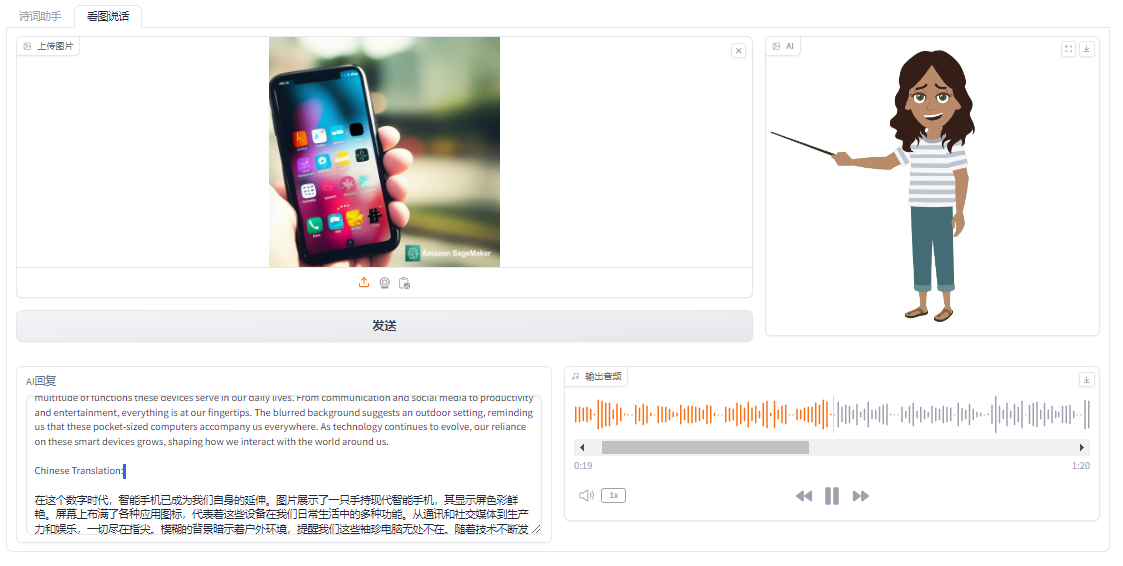
2.AI看图说话
用户上传图像,助手会对图像内容进行分析,并根据图进行中英文写作,并通过TTS阅读作品。
问题与解决方案
| id | 问题分析 | 解决方案 |
|---|---|---|
| 1 | 知识库数据质量参差不齐 | 对原始数据进行清洗、筛选、切分和元数据抽取,提高知识库质量。 |
| 2 | 图片过大情况下会导致模型token超限 | 通过OpenCV进行图像压缩 |
| 3 | 多模态场景模型支持问题 | 针对不同场景选择最优的SaaS大模型实现快速接入,同时结合本地部署的语音小模型实现多模态交互。 |
项目总结与展望
项目评估
本项目取得了不错的成果,开发出了集成AI诗词助手和AI看图说话功能的智能对话系统,可以本地CPU环境运行,具有一定的创新性和实用价值。但同时也存在一些不足,例如知识库RAG召回、模型生成质量等方面还有优化和提升空间。
未来方向
- 优化RAG,实现bm25+向量多路召回
- 优化Chain逻辑以及场景提示词,提升模型生成质量
- 探索更多应用场景,开发外部Agent以拓展助手的应用范围
附件与参考资料
- https://python.langchain.com/
- https://github.com/kinfey/Microsoft-Phi-3-NvidiaNIMWorkshop/tree/main/ppt
- https://github.com/modelscope/FunASR
- https://build.nvidia.com/explore/discover
- https://github.com/rany2/edge-tts/